OkCupid Dataset Analysis for Machine Learning
🇨🇦How Ethnicity, Height, and Body Type Effect Mating Success?
Book a callHow Ethnicity, Height, and Body Type Effect Mating Success?
Book a call
This blog article is part 1 of a series. The whole series constitutes a university machine learning project.
Here are the other parts of the series:
Kaggle is a website that hosts a series of Datasets.
For my project, I found this dataset that I will be using:
I download the ZIP from this URL:
https://www.kaggle.com/datasets/andrewmvd/okcupid-profiles?resource=download
After I execute the code below:
./chapter2/data2/load2.py
import os
import zipfile
# Define the path to the zip file and where to extract
dating_zip_path = os.path.join("datasets", "dating", "dating.zip")
extract_path = os.path.join("datasets", "dating")
# Function to extract zip file
def extract_zip(zip_path, extract_to):
with zipfile.ZipFile(zip_path, 'r') as zip_ref:
zip_ref.extractall(extract_to)
print(f"Extracted to {extract_to}")
# Call the function to extract dating.zip
extract_zip(dating_zip_path, extract_path)import os
import pandas as pd
# Define the path to the dating dataset folder
DATING_PATH = os.path.join("datasets", "dating")
# Function to load the dating CSV file
def load_dating_data(dating_path=DATING_PATH):
csv_path = os.path.join(dating_path, "okcupid_profiles.csv") # Adjust the filename if necessary
return pd.read_csv(csv_path)
# Load the dating data
dating_data = load_dating_data()
# Display the first few rows of the dataset
print(dating_data.head())
The code generates the CVS in this directory:
./datasets/dating/okcupid_profiles.csv
To better understand our data, we will run a series of commands using Python 3 and a Jupiter notebook.
Below, we can see the first 3 rows of the data and the column names.

Below are the columns with the number of valid entries for each. We can also see the data type that each column contains:
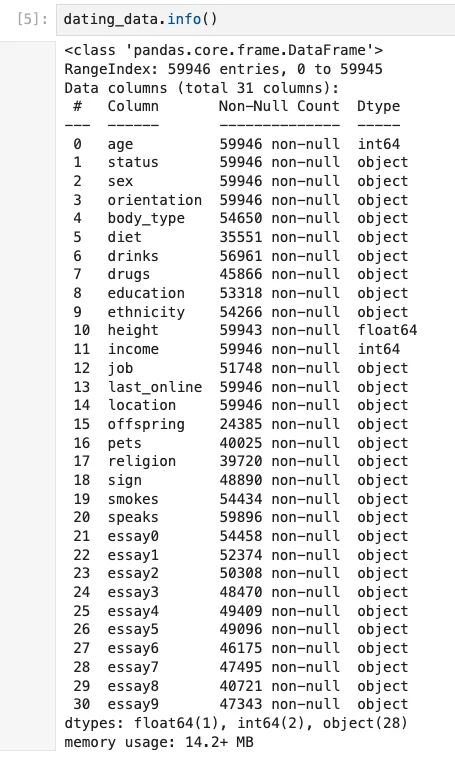
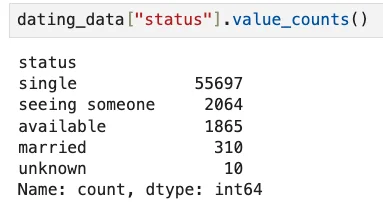
Note that 'status,' for example, is a categorical attribute:
We execute the code below to count the total number of entries that exist per category in the 'status' column:
To retrieve statistics about columns that are of numerical type, we can execute the following:
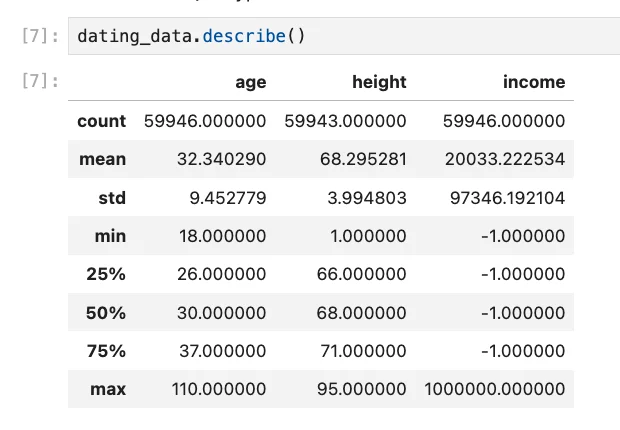
So, the units for the 3 columns of numerical type are:
Now we plot the histograms of the numeric columns (age, height and income (features)):
On the notebook run
%matplotlib inline
import matplotlib.pyplot as plt
dating_data.hist(bins=50, figsize=(20,15))
plt.show()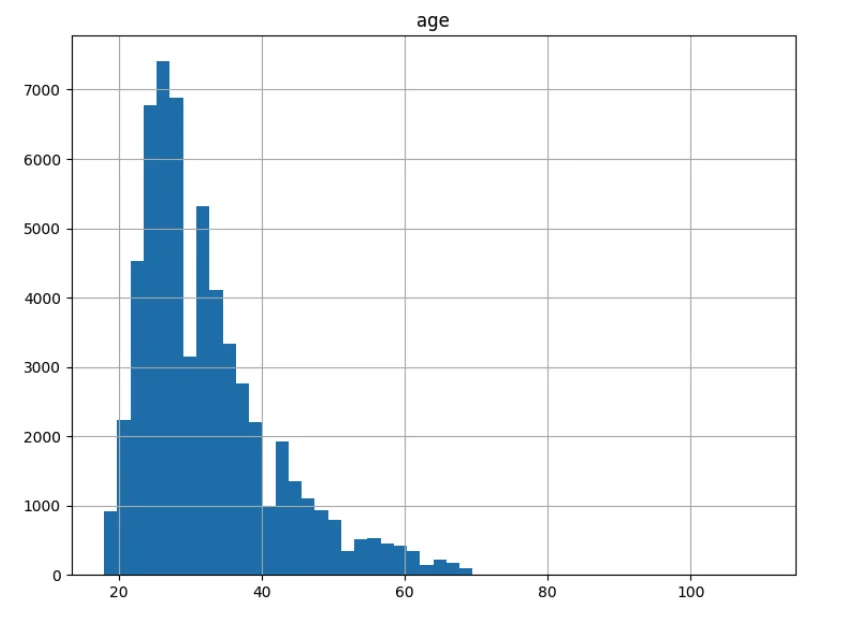
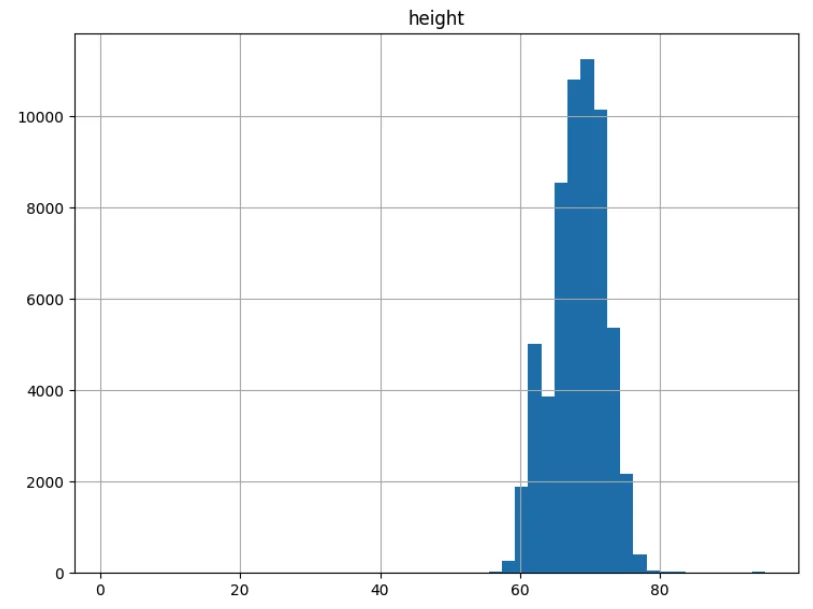
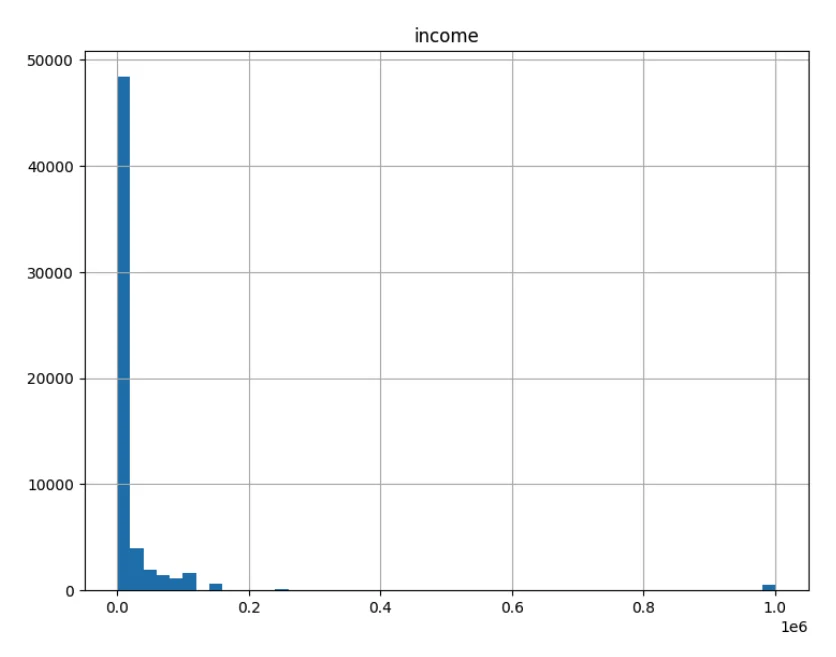
In this project, I am building a machine learning model to predict a combined label of relationship status and whether an individual has offspring. The goal is to understand how various demographic and physical characteristics contribute to relationship and parental status, specifically for males. The current features used for prediction, including ethnicity, body type, and height, are key personal attributes that may influence these outcomes, making them crucial to the model's accuracy and relevance to our study.
Additional features, such as drinking habits, drug use, smoking status, religion, and languages spoken, could be incorporated to further enhance the model. By extending the feature set, the model could gain more insight into lifestyle and cultural factors that affect relationship dynamics and family structure. This would provide a more comprehensive understanding of the interactions between physical, demographic, and behavioural traits in predicting life choices related to family and relationships.
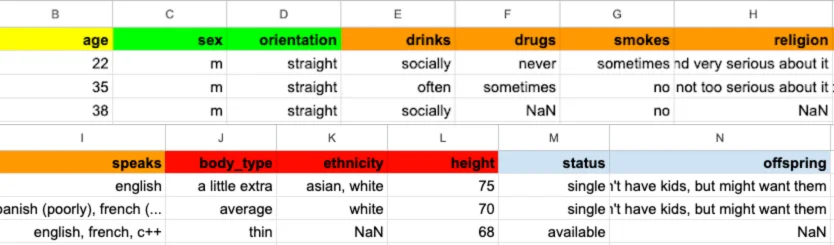
Below the colour legend shows how the data will be dealt with:
Copyright © 2024
| Powered by: Earnanswers

